News and Events

Xavier Intes (RPI) and Margarida Barroso (AMC) have been selected for funding of a new National Cancer Institute (NCI) R01 grant focusing on "Role of tumor biomechanics on drug-receptor engagement". This is fantastic news, particularly considering the current funding climate and the historically competitive nature of NCI.

Rensselaer Polytechnic Institute (RPI) is hosting the Natural & Biobased Cosmetic Ingredients Conference April 7–9, 2026, at the university's Center for Biotechnology and Interdisciplinary Studies (CBIS) in Troy, N.Y. The three-day event draws cosmetic scientists, biotechnologists, and product developers from both industry and academia to discuss emerging research and commercial developments in sustainable cosmetic ingredients.

Many disease-causing bacteria — including pathogens that can cause cholera, meningitis, and certain types of pneumonia — contain an enzyme called Na⁺-NQR. The enzyme is essentially a pump that helps bacteria generate energy by moving sodium ions across their cell membranes while transferring electrons.

The Shirley Ann Jackson, Ph.D. Center for Biotechnology and Interdisciplinary Studies (CBIS) at Rensselaer Polytechnic Institute (RPI) was recently awarded $1 million in federal funds as part of the Congressionally Directed Spending program to advance RPI research and translational efforts related to pharmaceuticals, biopolymers, and food production.
Professor Douglas Swank has been selected to receive the Marion J. Siegman Annual Award Lectureship from the American Physiological Society!
Dr. Swank's work has helped advance how we understand how muscles function, contributing important insights that support future discoveries in health and medicine. As part of this recognition, he has been invited to present an award lecture at the American Physiology Summit, taking place April 23-26 in Minneapolis.

This semester, the RPI-Mt. Sinai Center for Engineering and Precision Medicine (CEPM) welcomed the inaugural cohort of students in the center’s Ph.D. program in health sciences engineering jointly offered by RPI and Icahn School of Medicine at Mount Sinai.

The Multi-Organ Approach to Address Diseases Following Estrogen Loss (MODEL) program aims to map the entire biological landscape of menopause
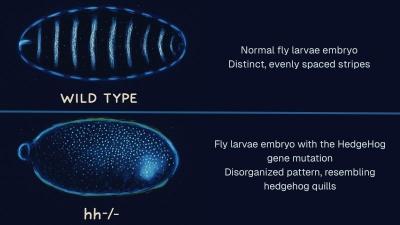
A discovery with major implications for cancer treatment has been made by a team of researchers from Rensselaer Polytechnic Institute (RPI), the University of Nebraska Medical Center (UNMC), University of Binghamton, and SUNY College of Environmental Science and Forestry.

New research from Rensselaer Polytechnic Institute (RPI) could help shape the future of artificial intelligence by making AI systems less resource-intensive, higher performing, and designed to emulate the human brain.
